
本文中使用的 Kafka 版本为 v3.3.2
引言 #
Kafka MirrorMaker2 是 Kafka 官方提供的跨集群数据复制工具, 它是基于 Kafka Connect 框架构建的。MirrorMaker2 支持多种部署模式, 包括 Dedicated 模式和 Connect 集群模式,还有 standalone 模式。
其中, Dedicated 模式有一个启动脚本 kafka-mirror-maker.sh, 该脚本会启动一个独立的 MirrorMaker2 实例, 而不需要依赖 Kafka Connect 集群。Dedicated 模式适合小规模的复制任务, 但在大规模部署中, 它缺乏可扩展性和高可用性。
相比之下, Connect 集群模式则是先搭建出一个 Kafka Connect 集群, 再提交 MirrorMaker2 的 MirrorSourceConnector 任务。这种模式下, 可以通过增加或减少 Connect 工作节点来动态调整复制任务的资源, 具备更好的弹性和容错能力。
当然配置上也会更复杂一些, 需要管理 Connect 集群的配置和任务。
那么, 如果我们已经在使用 Dedicated 模式部署了 MirrorMaker2, 但现在需要切换到 Connect 集群模式, 应该如何操作呢? 本文将介绍从 Dedicated 模式迁移到 Connect 集群模式时,怎么处理已经同步的 offset 进度, 以确保数据的一致性和连续性。
Kafka Connect 的设计 #
Kafka Connect 是 Apache Kafka 生态系统中的框架和工具集,旨在在 Kafka 和其他数据系统(例如数据库、云服务和文件系统)之间可靠且可扩展地传输数据。主要特性包括分布式架构、基于配置的操作以及对数据转换和各种序列化格式的支持,使数据集成更简单、更解耦。
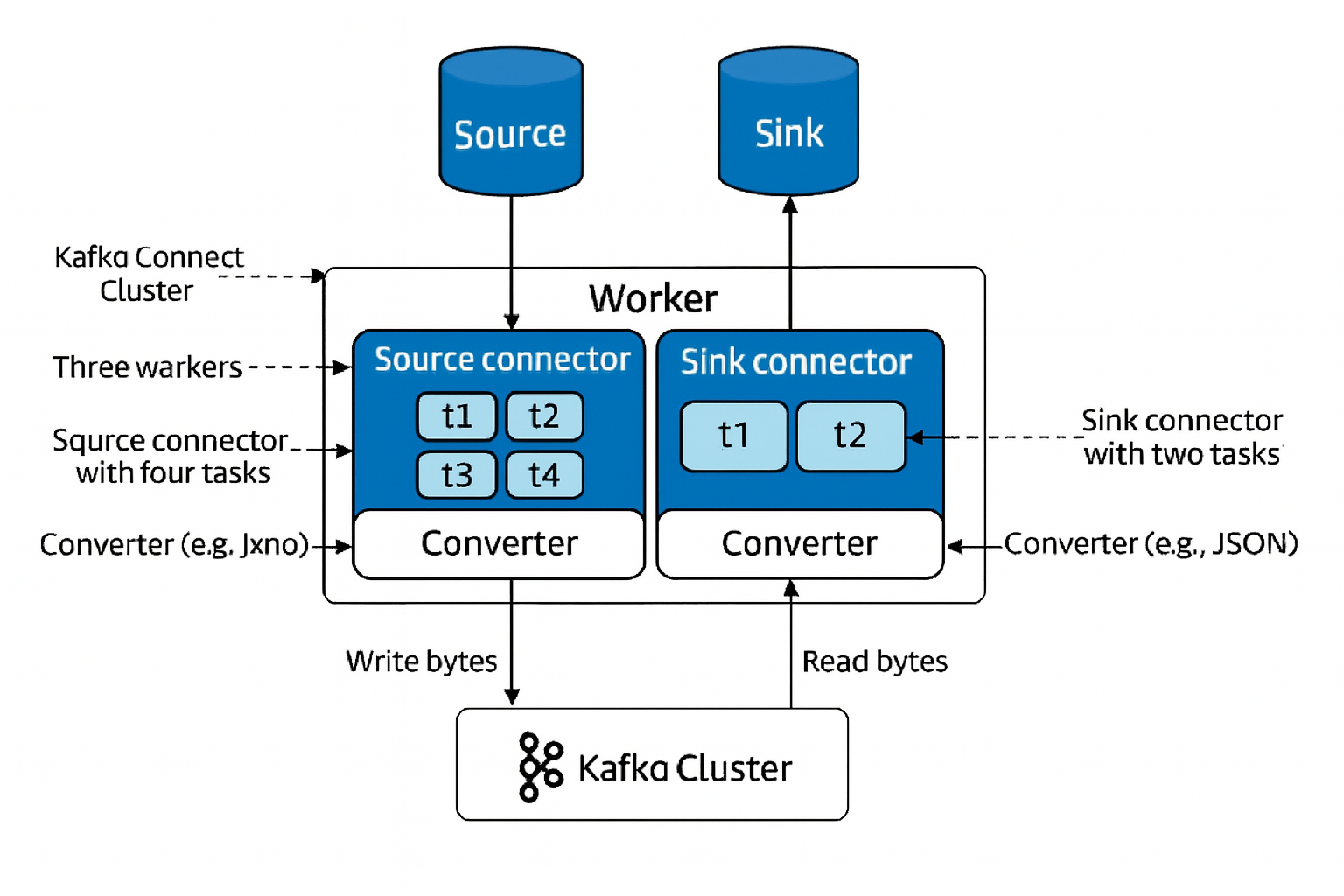
在整个框架中有以下几个核心概念:
-
Workers: 负责实际执行任务执行, 每个 Worker 都有一个线程池, 用于执行多个任务。
-
Connectors: 连接其他系统和 kafka 的组件,也是整个 Kafka Connect 框架中最重要的扩展点。
- Source Connector: 从其他系统(MySQL, Mongo)导入数据到 Kafka。
- Sink Connector: 将 Kafka 中的数据导出到其他系统。
Connector 自身不执行数据复制,而是负责将整个复制任务拆分成一组可以执行的
Task交给 Kafka ConnectWorker执行。因此要实现一个 Connector 也需要确定要使用的 Task 类)。
-
Tasks: 则负责实际执行任务执行。
- Source Task: 从源系统读取数据, 并将其写入 Kafka。
- Sink Task: 从 Kafka 读取数据, 并将其写入目标系统。
除了上述核心组件外, Kafka Connect 还包括以下几个重要概念:
- Converters: Kafka Connect 要和外部系统交互,不可避免的需要对数据进行序列化和反序列化。Converters 负责将数据从一种格式转换为另一种格式。
- Transformers: 用于在数据复制过程中对数据进行转换和处理, 比如字段重命名,增加/删除字段等等,当然也可以进行自定义。
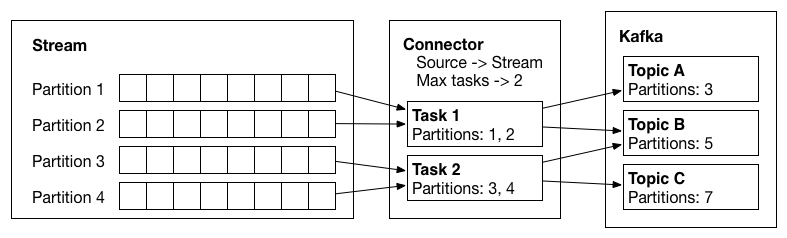
Kafka Connect 会在 Connector 实例运行时, 跟踪其偏移量,以便连接器在发生故障或者维护时,可以从先前的位置恢复。参考 Kafka Connect 文档。
在对 Kafka Connect 框架有了一定的了解后,我们就可以再深入去理解 MirrorMaker 的设计原理了,一言以蔽之:一个把数据从源 Kafka 复制到目标 Kafka 的 MirrorSourceConnector。
思考题:为什么是实现 SourceConnector 而不是实现 SinkConnector?
MirrorSourceConnector 的设计 #
这部分不会关注两种部署模式的区别,重点关注 MirrorMaker2 的核心组件
MirrorSourceConnector。至于MirrorCheckpointConnector是用来同步 groups,一个是用来探测与 kafka 集群的联通性,按需使用即可。
MirrorMaker2 的核心组件是 MirrorSourceConnector, 它负责从源集群读取数据并写入目标集群。MirrorSourceConnector 实现了 Kafka Connect 的 SourceConnector 类, 由此可见它的调度和任务管理都依赖于 Kafka Connect 框架。
MirrorSourceConnector 的主要作用就是把源集群的 topic 数据复制到目标集群。它的基本工作流程可以分为以下几个阶段:
- 初始化
- Task定义和任务分配
- 动态调整/维护
1. 初始化 #
这部分逻辑集中在 MirrorSourceConnector 的 start 方法中, 该方法会读取配置参数, 并初始化一些内部状态, 包括:
配置解析: 通过 MirrorConnectorConfig 解析配置参数(如源/目标集群别名、复制策略、过滤规则等)。若连接器未启用(config.enabled=false),则直接返回。
资源初始化: 创建源/目标集群的 AdminClient(用于集群管理操作)、Scheduler(用于定时任务),并初始化 replicationPolicy( topic 命名转换策略)、topicFilter( topic 过滤规则)等核心组件。
初始任务调度:
通过 Scheduler 执行一次性初始化任务:
- 创建 offset-syncs 主题(用于同步消费者偏移量)。
- 加载源/目标集群的初始 topic-partition 元数据。
- 在目标集群创建缺失的 topic 或分区。
2. Task定义和任务分配 #
Task 是实际执行数据复制的工作单元,这也是 Kafka Connect 的概念。MirrorSourceConnector 对应的 Task 类是 MirrorSourceTask。
参见下代码片段:
@Override
public Class<? extends Task> taskClass() {
return MirrorSourceTask.class;
}
// divide topic-partitions among tasks
// since each mirrored topic has different traffic and number of partitions, to balance the load
// across all mirrormaker instances (workers), 'roundrobin' helps to evenly assign all
// topic-partition to the tasks, then the tasks are further distributed to workers.
// For example, 3 tasks to mirror 3 topics with 8, 2 and 2 partitions respectively.
// 't1' denotes 'task 1', 't0p5' denotes 'topic 0, partition 5'
// t1 -> [t0p0, t0p3, t0p6, t1p1]
// t2 -> [t0p1, t0p4, t0p7, t2p0]
// t3 -> [t0p2, t0p5, t1p0, t2p1]
@Override
public List<Map<String, String>> taskConfigs(int maxTasks) {
if (!config.enabled() || knownSourceTopicPartitions.isEmpty()) {
return Collections.emptyList();
}
int numTasks = Math.min(maxTasks, knownSourceTopicPartitions.size());
List<List<TopicPartition>> roundRobinByTask = new ArrayList<>(numTasks);
for (int i = 0; i < numTasks; i++) {
roundRobinByTask.add(new ArrayList<>());
}
int count = 0;
for (TopicPartition partition : knownSourceTopicPartitions) {
int index = count % numTasks;
roundRobinByTask.get(index).add(partition);
count++;
}
return roundRobinByTask.stream().map(config::taskConfigForTopicPartitions)
.collect(Collectors.toList());
}
从上代码可以看到, MirrorSourceConnector 会根据配置的 maxTasks 参数, 将所有需要复制的 topic-partition 划分成多个子集, 每个子集对应一个 Task 的配置。划分策略采用 round-robin 方式, 以尽量均衡每个 Task 的负载。
使用时,需要注意 task 数量的设置, 合理的根据任务来设置 task 数量,避免过多或过少。
3. 持续维护 #
MirrorSourceConnector Scheduler 会定期执行维护任务, 以确保复制过程的一致性。主要包括:
- 同步 topic 的 ACL 和 配置。
- 刷新 topic 的分区信息,若发现源集群新增分区或目标集群缺失分区,会触发
computeAndCreateTopicPartitions,在目标集群创建 topic 或扩容分区。
MirrorSourceTask 的设计 #
MirrorSourceTask 实现了 SourceTask, 它负责实际的数据复制工作。其主要工作流程可以分为以下几个阶段:
- 初始化
- 数据拉取和写入
- 偏移量管理(这里特指 topic 同步的 offset 进度)
1. 初始化 #
配置解析: 加载连接器任务配置(如源集群别名、偏移量同步主题、消费者超时时间等)。
资源初始化: 创建 Kafka 消费者(拉取源集群数据)、Kafka 生产者(发送偏移量同步信息)、信号量(控制消费者并发访问)等核心资源。
分区与偏移量准备:
- 从
<offset.storage.topic>主题加载历史偏移量(通过loadOffsets方法)。 - 将消费者分配到指定分区,并定位到上次复制的偏移量位置(
consumer.seek)。
@Override
public void start(Map<String, String> props) {
MirrorTaskConfig config = new MirrorTaskConfig(props);
// 初始化消费者、生产者 等资源
consumer = MirrorUtils.newConsumer(config.sourceConsumerConfig());
offsetProducer = MirrorUtils.newProducer(config.offsetSyncsTopicProducerConfig());
// 加载历史偏移量并定位消费者
Map<TopicPartition, Long> topicPartitionOffsets = loadOffsets(config.taskTopicPartitions());
consumer.assign(topicPartitionOffsets.keySet());
topicPartitionOffsets.forEach(consumer::seek);
}
其中 loadOffsets 的实现在 Dedicated 模式和 Connect 模式下是不同的:
- 在 Dedicated 模式下, 偏移量存储在
mm2-offsets.<source-cluster>主题中, 需要从该主题读取偏移量。 - 在 Connect 模式下, 偏移量存储在
<offset.storage.topic>主题中, 需要从该主题读取偏移量。
但无论哪种模式, 读取偏移量的逻辑都是类似的:
依赖于 OffsetStorageReader 接口, 同时在 OffsetStorageReader 的具体实现 OffsetStorageReaderImpl 中又依赖于 OffsetBackingStore 来具体决定偏移量的存储介质(如 Kafka 主题 、文件 等,内存等)。
MirrorMaker2 使用的是 KafkaOffsetBackingStore 来存储偏移量, 顾名思义, 它是基于 Kafka 主题的存储方式, 也就是 mm2-offsets.<source-cluster>.internal 或 <offset.storage.topic> 主题。
offset 主题中的消息格式如下,Key 和 Value 都是序列化后的字节数组:
["<connector-name>",{"cluster":"<source-cluster-alias>","partition":<partition>,"topic":"<topic-name>"}] // Key
{"offset": <offset>} // Value
在 Dedicated 模式下, <connector-name> 通常是 MirrorSourceConnector,而在 Connect 模式下, <connector-name> 则是用户创建的 Connector 名称。
‼️ 所以我们也就知道了,MirrorMaker2 在启动时,会尝试 恢复 之前的复制进度(偏移量),以确保数据复制的连续性和一致性。只是两种模式下,偏移量的存储位置不同而已。
2. 数据拉取和写入 #
MirrorSourceTask 的拉取逻辑由 poll 方法实现, 它由 Kafka Connect 框架控制调用。poll 方法的主要职责是从源集群拉取数据, 并将其转换为 Connect 框架的 SourceRecord 以供后续处理。
@Override
public List<SourceRecord> poll() {
// ...
try {
ConsumerRecords<byte[], byte[]> records = consumer.poll(pollTimeout);
List<SourceRecord> sourceRecords = new ArrayList<>(records.count());
for (ConsumerRecord<byte[], byte[]> record : records) {
SourceRecord converted = convertRecord(record);
sourceRecords.add(converted);
TopicPartition topicPartition = new TopicPartition(converted.topic(), converted.kafkaPartition());
}
// 省略部分代码
return sourceRecords;
} catch (WakeupException e) {
// Ignore exception handling
}
}
SourceRecord convertRecord(ConsumerRecord<byte[], byte[]> record) {
String targetTopic = formatRemoteTopic(record.topic()); // 处理为 <source-cluster-alias>.<topic>
Headers headers = convertHeaders(record);
return new SourceRecord(
MirrorUtils.wrapPartition(new TopicPartition(record.topic(), record.partition()), sourceClusterAlias),
MirrorUtils.wrapOffset(record.offset()),
targetTopic, record.partition(),
Schema.OPTIONAL_BYTES_SCHEMA, record.key(),
Schema.BYTES_SCHEMA, record.value(),
record.timestamp(), headers);
}
3. 偏移量管理 #
Kafka Connect 框架会自动管理偏移量的提交, 因此 MirrorSourceTask 不需要显式地提交偏移量。框架会定期将偏移量写入 <offset.storage.topic> 主题, 以确保在任务重启时能够恢复到正确的位置。
在 poll 方法中已经在 SourceRecord 中封装了偏移量信息, 框架会根据这些信息来更新偏移量。
KafkaOffsetBackingStore 的设计 #
前面提到了 MirrorSourceTask 使用了 KafkaOffsetBackingStore 来管理 topic 同步的 offset 进度,那么它具体是怎么进行管理的?
如果只进不出,topic 随着时间的推移里面的消息会越来越多,它怎么从这么多数据中获取到正确的偏移量值?投递进去的消息难道就一直保存着吗?
在 KafkaOffsetBackingStore 关于这些 topic 的创建如下,可以看到指定了 topic 为 compacted:
protected NewTopic newTopicDescription(final String topic, final WorkerConfig config) {
Map<String, Object> topicSettings = config instanceof DistributedConfig
? ((DistributedConfig) config).offsetStorageTopicSettings()
: Collections.emptyMap();
return TopicAdmin.defineTopic(topic)
.config(topicSettings) // first so that we override user-supplied settings as needed
.compacted()
.partitions(config.getInt(DistributedConfig.OFFSET_STORAGE_PARTITIONS_CONFIG))
.replicationFactor(config.getShort(DistributedConfig.OFFSET_STORAGE_REPLICATION_FACTOR_CONFIG))
.build();
}
而 compacted 实际对应了 topic 的 cleanup.policy = compact。
public NewTopicBuilder compacted() {
this.configs.put(CLEANUP_POLICY_CONFIG, CLEANUP_POLICY_COMPACT);
return this;
}
KafkaOffsetBackingStore 实现了 OffsetBackingStore,它实际又依赖了 KafkaBasedLog, 它明确的注释了:
KafkaBasedLog provides a generic implementation of a shared, compacted log of records stored in Kafka that all clients need to consume and, at times, agree on their offset / that they have read to the end of the log.
其内部创建了一个从 earliest 位点开始消费的 consumer,用来读取已存储的偏移量信息。
protected Consumer<K, V> createConsumer() {
// Always force reset to the beginning of the log since this class wants to consume all available log data
consumerConfigs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// Turn off autocommit since we always want to consume the full log
consumerConfigs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
return new KafkaConsumer<>(consumerConfigs);
}
/**
* This method finds the end offsets of the Kafka log's topic partitions, optionally retrying
* if the {@code listOffsets()} method of the admin client throws a {@link RetriableException}.
*/
private void readToLogEnd(boolean shouldRetry) {
Set<TopicPartition> assignment = consumer.assignment();
Map<TopicPartition, Long> endOffsets = readEndOffsets(assignment, shouldRetry);
log.trace("Reading to end of log offsets {}", endOffsets);
while (!endOffsets.isEmpty()) {
Iterator<Map.Entry<TopicPartition, Long>> it = endOffsets.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<TopicPartition, Long> entry = it.next();
TopicPartition topicPartition = entry.getKey();
long endOffset = entry.getValue();
long lastConsumedOffset = consumer.position(topicPartition);
if (lastConsumedOffset >= endOffset) {
log.trace("Read to end offset {} for {}", endOffset, topicPartition);
it.remove();
} else {
log.trace("Behind end offset {} for {}; last-read offset is {}",
endOffset, topicPartition, lastConsumedOffset);
poll(Integer.MAX_VALUE);
break;
}
}
}
}
简单总结一下,基于 kafka 的 offset 存储,利用了 kafka compact 机制来保存 offset 进度信息,这样可以避免消息量无限制增长。在需要从 kafka 中恢复数据时,则从头开始消费整个 topic 中的消息,保存最新的偏移量信息。
迁移 #
经过前面的介绍,我们已经了解了 MirrorMaker2 的工作原理和偏移量管理机制。那么, 如果我们已经在使用 Dedicated 模式部署了 MirrorMaker2, 现在想要切换到 Connect 集群模式, 应该如何操作呢?
这里考虑两个问题:
- Kafka Connect 集群应该如何搭建?
- 怎么迁移才能保证数据的一致,不会重复或丢失?
搭建 Kafka Connect 集群 #
Kafka Connect 集群的搭建可以参考官方文档或其他相关资料, 这里不做过多赘述。
https://docs.confluent.io/platform/current/connect/userguide.html
如何迁移进度 #
MirrorMaker2 在 Dedicated 模式下运行一段时间后,会在 TARGET Kafka 集群 mm2-offsets.<source-cluster>.internal 主题中存储偏移量信息。而在 Connect 模式下, 偏移量信息则存储在 <offset.storage.topic> 主题中。如果我们不做任何处理,那么在切换到 Connect 模式后, 任务会从 <offset.storage.topic> 主题中读取偏移量, 由于该主题中没有任何数据, 任务会从头开始复制数据, 这会导致大量的重复数据。
如果业务能够容忍重复数据, 那么可以直接切换, 但大多数场景下, 我们希望数据复制是连续且一致的。
那么就需要我们把 mm2-offsets.<source-cluster>.internal 主题中的偏移量数据, 迁移到 <offset.storage.topic> 主题中, 那么在切换到 Connect 模式后, 任务就能从正确的位置继续复制数据, 避免重复或丢失。
这个转换过程也很简单, 只需要编写一个脚本, 从 mm2-offsets.<source-cluster>.internal 主题中读取偏移量数据, 然后按照 <offset.storage.topic> 主题的格式写入即可。
推荐将 offsets 数据保存到文件或者其他存储介质中, 方便人工验证或者调整。
举例来说:
假如 mm2-offsets.source.internal 主题中有如下消息:
Key: ["MirrorSourceConnector",{"cluster":"source","partition":0,"topic":"test-topic"}]
Value: {"offset": 12345}
那么我们需要把它转换为 <offset.storage.topic> 主题中的消息:
Key: ["mm2-source-connector",{"cluster":"source","partition":0,"topic":"test-topic"}]
Value: {"offset": 12345}
两者唯一的区别在于 Key 中的 connector 名称,如果 source.cluster.alias(cluster) 不同, 也需要做相应的调整。
脚本举例如下:
offset 迁移示例
def extract_dedicated_offsets(brokers, dedicated_offset_topic, output_file):
"""从专用模式的 offset topic 中提取 offset 信息并保存到文件"""
print(f"从 {dedicated_offset_topic} 提取 offsets, 创建 consumer 连接到 {brokers}")
consumer = KafkaConsumer(
dedicated_offset_topic,
bootstrap_servers=brokers,
auto_offset_reset='earliest',
enable_auto_commit=False,
consumer_timeout_ms=10000, # 10秒内没有新消息就退出
key_deserializer=lambda x: json.loads(x.decode('utf-8')) if x else None,
value_deserializer=lambda x: json.loads(x.decode('utf-8')) if x else None
)
print("开始消费消息...")
# 只保留每个 topic-partition 的最新 offset
offsets = {}
for message in consumer:
if message.key and message.value:
if message.key[0] != "MirrorSourceConnector":
# 只处理 MirrorSourceConnector 的消息
continue
# 专用模式格式: Key[1] = {"cluster": "...", "partition": ..., "topic": "..."}
partition_info = message.key[1]
cluster = partition_info["cluster"]
topic = partition_info["topic"]
partition = partition_info["partition"]
offset = message.value["offset"]
# 过滤掉内部 topic (heartbeats, checkpoints 等)
if topic.endswith('heartbeats') or 'checkpoints' in topic or 'internal' in topic:
print(f"跳过内部 topic: {topic}")
continue
# 使用 topic-partition 作为唯一标识,保留最新的 offset
key = f"{cluster}-{topic}-{partition}"
offsets[key] = {
"cluster": cluster,
"topic": topic,
"partition": partition,
"offset": offset
}
print(f"提取 offset: {key} -> {offset}")
else:
print(f"跳过其他消息: {message.key[0] if message.key else 'None'}")
consumer.close()
# 保存到文件
with open(output_file, 'w') as f:
json.dump(offsets, f, indent=2)
print(f"提取了 {len(offsets)} 个 offset 记录到 {output_file}")
def publish_connect_offsets(brokers, connect_offset_topic, connector_name, input_file):
"""从文件读取 offset 信息,转换为 Connect 格式并发布到 Connect offset topic"""
# 从文件读取 offset 信息
with open(input_file, 'r') as f:
offsets = json.load(f)
producer = KafkaProducer(
bootstrap_servers=brokers,
key_serializer=lambda x: json.dumps(x, separators=(',', ':')).encode('utf-8'),
value_serializer=lambda x: json.dumps(x, separators=(',', ':')).encode('utf-8')
)
success_count = 0
for offset_data in offsets.values():
# 转换为 Connect 格式
connect_key = [
connector_name,
{
"cluster": offset_data["cluster"],
"partition": offset_data["partition"],
"topic": offset_data["topic"]
}
]
connect_value = {
"offset": offset_data["offset"]
}
try:
# print(f"发布 offset: {connect_key} -> {connect_value} 到 {connect_offset_topic}")
future = producer.send(connect_offset_topic, key=connect_key, value=connect_value)
future.get(timeout=10)
success_count += 1
except KafkaError as e:
print(f"发送 offset 失败: {e}", file=sys.stderr)
producer.flush()
producer.close()
print(f"成功发布了 {success_count}/{len(offsets)} 个 offset 记录")
操作步骤 #
- 准备好 Kafka Connect 集群环境(需要搭建在 Target 集群中)
- 选择合适的时机停止 dedicated 模式的 MirrorMaker2 服务
- 运行 extract_dedicated_offsets 提取出 offset (从
mm2-offsets.<source-cluster-alias>.internal中提取) - 运行 publish_connect_offsets 写入 offset (写入
<offset.storage.topic>) - 在 Kafka Connect 中创建 Connector 任务
curl -X POST -H "Content-Type: application/json" --data @mm2-connector.json http://localhost:8083/connectors
connector 配置文件简单示例
更多配置请参考 MirrorSourceConnector 配置
{
"name": "mm2-source-connector", // 连接名称, 可以自定义
"config": {
"connector.class": "org.apache.kafka.connect.mirror.MirrorSourceConnector", // 连接类, 固定值
"source.cluster.alias": "source", // 源集群别名, 可以自定义,迁移时写入 <offset.storage.topic> 的值
"target.cluster.alias": "target", // 目标集群别名, 可以自定义
"source.cluster.bootstrap.servers": "kafka-source:9092", // 源集群 bootstrap.servers, 迁移时需要指向源集群
"target.cluster.bootstrap.servers": "kafka-target:9092", // 目标集群 bootstrap.servers, 迁移时需要指向目标集群
"topics": "test-topic,test-topic-second", // 要迁移的 topic 列表, 可以自定义
"tasks.max": 2 // 任务数量, 可以根据集群资源调整
// ... 更多配置
}
}
总结 #
本文深入探讨了 Apache Kafka MirrorMaker2 的设计原理和实现机制,并详细介绍了从 Dedicated 模式迁移到 Connect 集群模式的完整方案。
核心要点回顾 #
架构设计:
- MirrorMaker2 基于 Kafka Connect 框架构建,通过 MirrorSourceConnector 实现跨集群数据复制
- 支持 Dedicated 模式(独立运行)和 Connect 集群模式(分布式部署)两种部署方式
- 采用 round-robin 策略将 topic-partition 分配给多个 Task,实现负载均衡
偏移量管理:
- 使用 KafkaOffsetBackingStore 基于 Kafka topic 存储偏移量信息
- 利用 Kafka 的 compact 机制避免偏移量数据无限增长
- Dedicated 模式存储在
mm2-offsets.<source-cluster>.internal,Connect 模式存储在<offset.storage.topic>
迁移策略:
- 通过提取和转换偏移量数据,确保迁移过程中数据复制的连续性
- 关键在于正确转换 connector 名称和集群别名,保持偏移量的一致性
- 迁移过程需要短暂停机,但可以避免数据重复或丢失
实践建议 #
-
选择合适的部署模式:小规模场景可选择 Dedicated 模式,大规模生产环境建议使用 Connect 集群模式以获得更好的可扩展性和高可用性
-
合理配置 Task 数量:根据 topic-partition 数量和集群资源合理设置
tasks.max,避免资源浪费或性能瓶颈 -
做好迁移规划:迁移前充分测试偏移量提取和转换脚本,选择业务低峰期进行迁移操作
-
监控和验证:迁移后密切监控数据复制状态,验证偏移量恢复的正确性
注意事项 #
- 本文基于 Kafka v3.3.2,不同版本的实现细节可能有所差异
- 未涉及 MirrorCheckpointConnector 和 MirrorHeartbeatConnector 的详细介绍,实际使用中需要根据场景考虑是否需要启用这些组件
- 对于消费者组偏移量同步的场景,需要额外的迁移策略
通过理解 MirrorMaker2 的内部机制,我们能够更好地运维和优化跨集群数据复制方案,确保数据的一致性和系统的稳定性。
参考 #
- Kafka Connect API
- Kafka Connect Configs
- Confluent - Kafka Connect Architecture
- Confluent - Kafka Connect Developer Guide
附 #
Connect 配置 #
Kafka Connect 的配置分为两个层面:
Worker 配置:控制 Connect 集群的基础行为
bootstrap.servers: Kafka 集群地址group.id: Connect 集群的唯一标识config.storage.topic: 存储 Connector 配置的内部主题,默认值为connect-configsoffset.storage.topic: 存储偏移量信息的内部主题,默认值为connect-offsetsstatus.storage.topic: 存储任务状态的内部主题,默认值为connect-status
Connector 配置:定义具体的数据复制任务
connector.class: 指定使用的 Connector 类tasks.max: 最大任务数量topics或topics.regex: 指定要处理的主题
其他特定于 Connector 的配置参数, 要参见相应的 Connector 源码或者文档。
MirrorConnector 配置 #
表格根据 [email protected]/MirrorConnectorConfig.java 整理而来。
| 配置项 | 描述 | 默认值 |
|---|---|---|
enabled |
是否启用源集群到目标集群的复制 | true |
topics |
要复制的主题。支持逗号分隔的主题名称和正则表达式 | .* (所有主题) |
topics.exclude |
排除的主题。支持逗号分隔的主题名称和正则表达式。排除规则优先于包含规则 | "" (无排除主题) |
groups |
要复制的消费者组。支持逗号分隔的组 ID 和正则表达式 | .* (所有组) |
groups.exclude |
排除的消费者组。支持逗号分隔的组 ID 和正则表达式。排除规则优先于包含规则 | "" (无排除组) |
config.properties.exclude |
不应复制的主题配置属性。支持逗号分隔的属性名称和正则表达式 | "" (无排除属性) |
topic.filter.class |
使用的 TopicFilter 类。选择要复制的主题 | org.apache.kafka.connect.mirror.DefaultTopicFilter |
group.filter.class |
使用的 GroupFilter 类。选择要复制的消费者组 | org.apache.kafka.connect.mirror.DefaultGroupFilter |
config.property.filter.class |
使用的 ConfigPropertyFilter 类。选择要复制的主题配置属性 | org.apache.kafka.connect.mirror.DefaultConfigPropertyFilter |
source.cluster.alias |
源集群别名 | source |
target.cluster.alias |
目标集群别名。用于指标报告 | target |
consumer.poll.timeout.ms |
轮询源集群时的超时时间 | 1000 (1 秒) |
admin.timeout.ms |
管理任务的超时时间(例如检测新主题) | 60000 (1 分钟) |
refresh.topics.enabled |
是否定期检查新主题和分区 | true |
refresh.topics.interval.seconds |
主题刷新频率 | 600 (10 分钟) |
refresh.groups.enabled |
是否定期检查新消费者组 | true |
refresh.groups.interval.seconds |
消费者组刷新频率 | 600 (10 分钟) |
sync.topic.configs.enabled |
是否定期配置远程主题以匹配其对应的上游主题 | true |
sync.topic.configs.interval.seconds |
主题配置同步频率 | 600 (10 分钟) |
sync.topic.acls.enabled |
是否定期配置远程主题 ACL 以匹配其对应的上游主题 | true |
sync.topic.acls.interval.seconds |
主题 ACL 同步频率 | 600 (10 分钟) |
emit.heartbeats.enabled |
是否向目标集群发送心跳 | true |
emit.heartbeats.interval.seconds |
心跳频率 | 1 (1 秒) |
emit.checkpoints.enabled |
是否将消费者偏移量复制到目标集群 | true |
emit.checkpoints.interval.seconds |
检查点频率 | 60 (1 分钟) |
sync.group.offsets.enabled |
是否将转换后的偏移量同步到目标集群的 __consumer_offsets(如果没有活跃消费者) | false |
sync.group.offsets.interval.seconds |
消费者组偏移量同步频率 | 60 (1 分钟) |
replication.policy.class |
定义远程主题命名约定的类 | org.apache.kafka.connect.mirror.DefaultReplicationPolicy |
replication.policy.separator |
远程主题命名约定中使用的分隔符 | . (点) |
replication.factor |
新创建的远程主题的复制因子 | 2 |
heartbeats.topic.replication.factor |
心跳主题的复制因子 | 3 |
checkpoints.topic.replication.factor |
检查点主题的复制因子 | 3 |
offset-syncs.topic.replication.factor |
偏移量同步主题的复制因子 | 3 |
offset.lag.max |
远程分区在重新同步之前可以落后的最大偏移量 | 100 (偏移量) |
offset-syncs.topic.location |
偏移量同步主题的位置(源集群/目标集群) | source |
metric.reporters |
用作指标报告器的类列表 | null (无额外报告器,默认启用 JMX) |
security.protocol |
与 broker 通信时使用的安全协议 | PLAINTEXT |
除此之外还有一些通用的 Kafka 配置,采用前缀匹配再合并的方式,处理先后顺序是:
<source/target>.cluster.* -> consumer.* -> <source/target>.producer.* -> 固定配置,参见下方 sourceConsumerConfig 代码处理顺序。
配置会被剪切掉前缀再合并到最终的 props 中。如:
source.cluster.bootstrap.servers其实对应的是bootstrap.servers配置。
Map<String, Object> sourceConsumerConfig() {
Map<String, Object> props = new HashMap<>();
// 1. 基础集群配置(如 source.cluster.bootstrap.servers)
props.putAll(originalsWithPrefix(SOURCE_CLUSTER_PREFIX));
// 2. 保留 Kafka 客户端配置(过滤非客户端属性)
props.keySet().retainAll(MirrorClientConfig.CLIENT_CONFIG_DEF.names());
// 3. 通用 consumer. 配置(如 consumer.fetch.min.bytes)
props.putAll(originalsWithPrefix(CONSUMER_CLIENT_PREFIX));
// 4. 源集群专用 consumer. 配置(如 source.consumer.max.poll.records,优先级最高)
props.putAll(originalsWithPrefix(SOURCE_PREFIX + CONSUMER_CLIENT_PREFIX));
// 5. 强制覆盖关键配置(如禁用自动提交、默认 earliest 偏移量)
props.put(ENABLE_AUTO_COMMIT_CONFIG, "false");
props.putIfAbsent(AUTO_OFFSET_RESET_CONFIG, "earliest");
return props;
}
| Key 前缀 | 描述 | 生效范围 |
|---|---|---|
producer.* |
通用生产者配置(如 producer.bootstrap.servers、producer.acks 等)。 | 同时作用于源集群和目标集群的生产者,除非被 source.producer. 或 target.producer. 覆盖。 |
consumer.* |
通用消费者配置(如 consumer.bootstrap.servers、consumer.group.id 等)。 | 同时作用于源集群和目标集群的消费者,除非被 source.consumer. 或 target.consumer. 覆盖。 |
source.producer.* |
源集群生产者的专用配置(优先级高于 producer.)。 | 仅用于源集群的生产者(如发送偏移量同步记录到 offsetSyncsTopic)。 |
source.consumer.* |
源集群消费者的专用配置(优先级高于 consumer.)。 | 仅用于源集群的数据拉取消费者(如从源集群主题拉取待复制数据)。 |
target.producer.* |
目标集群生产者的专用配置(优先级高于 producer.)。 | 仅用于目标集群的生产者(如复制数据到目标集群主题)。 |
target.consumer.* |
目标集群消费者的专用配置(优先级高于 consumer.)。 | 仅用于目标集群的消费者(如读取目标集群元数据或偏移量同步记录)。 |
producer.和consumer.前缀支持所有 Kafka 标准生产者/消费者配置(如 acks、retries、fetch.min.bytes 等),具体可参考 Kafka 官方文档配置: Consumer Config / Producer Config