需求和背景分析#
一提到定时任务的使用场景,我们肯定能想到很多场景,比如:
- 每天晚上12点执行一次清理数据的任务
- 每天凌晨1点给符合条件的用户发送推广邮件
- 每个月10号结算工资
- 每隔5分钟检查一次服务器的状态
- 每天根据用户的配置,给用户发送站内消息提醒
- …
从常见的场景中,我们可以提炼出一些定时任务的特点:
| 序号 | 特点 | 说明 |
|---|---|---|
| 1 | 定时 | 执行时间有规则 |
| 2 | 可靠 | 可以延迟执行,但不能不执行;可以不执行,但是不能多执行 |
| 3 | 并发(可能) | 某些场景下,可以运行多个 cron 进程来提高执行效率 |
| 4 | 可执行 | 这个有点废话了,但是这个关系到 cronjob 的设计,因此在这里还是提出来 |
但是作为一个系统来说,我们需要更多的功能来提升用户体验,保证平台的可靠和稳定。我们设想下以下的场景:
- 定时任务已经触发了,但是有没有执行,执行结果是什么?
- 如果一个定时任务长时间运行,那么它正常吗?
- 一个定时任务还在运行,但是下一个触发时机又到来了,该怎么办?
- 如果服务器资源已经处于高位,那么要被触发的任务还触发吗?
- …
最后,基本的访问控制,权限分配和API设计,这些都是系统功能的一部分,但不作为本文的重点考虑对象。
一些概念#
到这里我们可以提取一些概念,来帮助我们设计一个系统:
| 序号 | 名词 | 解释 |
|---|---|---|
| 1 | CronJob | 定时任务实例,描述定时任务资源的一个实体 |
| 2 | Job | 执行中的定时任务 |
| 3 | Scheduler | 调度器,负责触发 CronJob 执行和监控 Job 的执行状态;或许还会存储一些 CronJob 的状态 |
| 4 | JobRuntime | job 运行时,准备 Job 运行时需要的资源; 可以参考 k8s CRI |
这里 JobRuntime 是抽象化的概念,因为 Job 可以是k8s上的POD,也可以是物理机的进程,还可以是一个进程中的coroutine。
这几个概念的关联关系如图:

总结: 把定时任务平台分为了运行前和运行中两个阶段,通过调度器居中协调,达到两个目的:
- Scheduler 不负责 CronJob 的运行,减轻 Scheduler 的职责。
- JobRuntime 抽象化并独立设计,方便扩展。
关键点#
再总结一下设计过程中的关键点,如下图。
可以先忽略分布式相关的要点(large scale, reliable),先重点看下功能性的要点。
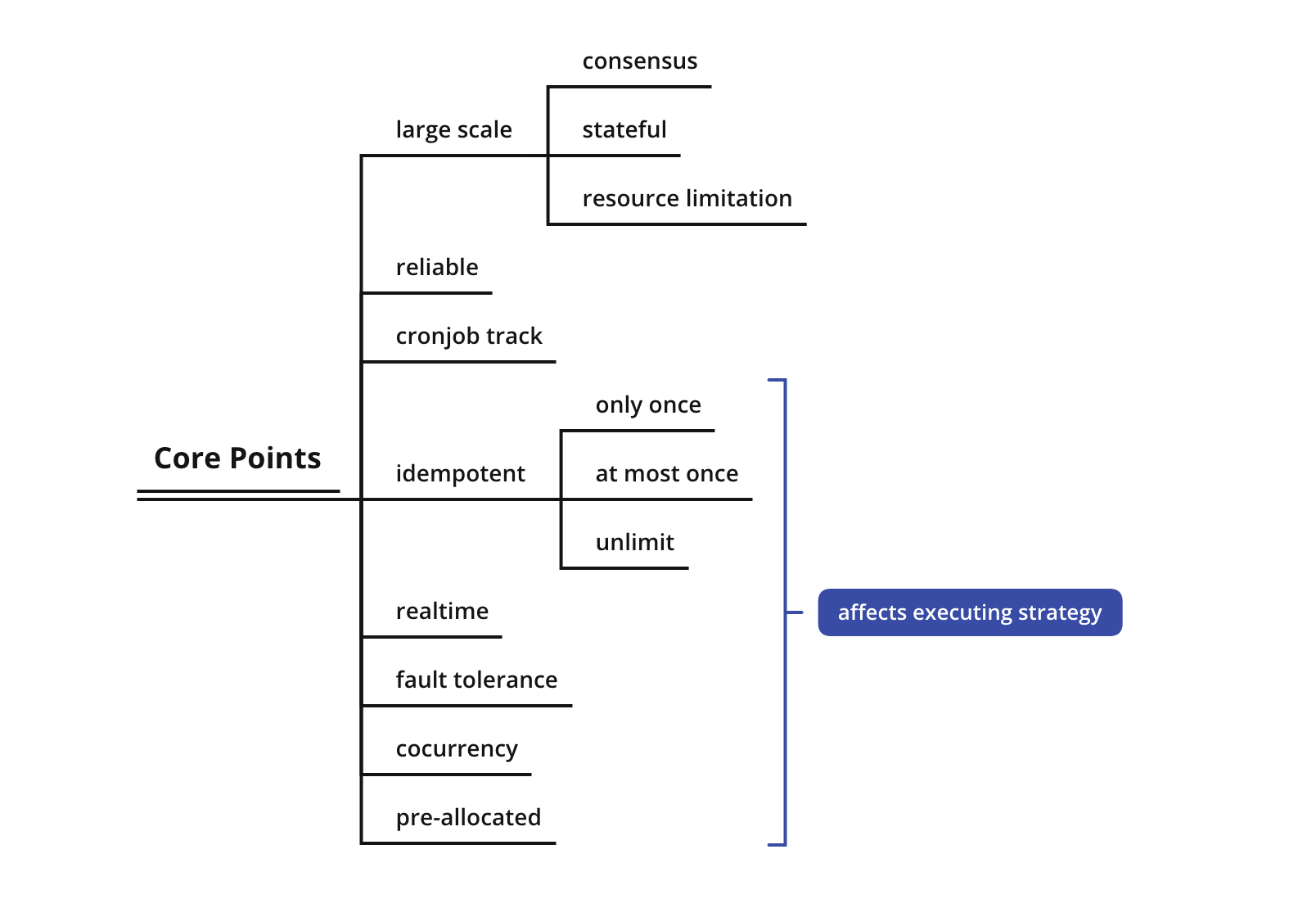
-
CronJob Track「定时任务跟踪」
感知 CronJob 的状态,并记录状态变化的历史记录,用于辅助 scheduler 实现一些策略调度。同时也能提供一些 CronJob 的运行数据,帮助用户调试和了解 CronJob 的健康状况。
-
Idempotent「幂等保证」
某些定时任务对执行次数是有要求的,作为提供服务的平台来说,需要尽最大努力保证任务执行。因此提出一些 “幂等级别” 供不同的定时任务使用。
- 只执行一次。一个 “CronJob” 一定会触发一次,但是这个比较难保证。
- 最多一次。可以不触发,但是不能触发多次。
- 可以重复执行。可以触发多次。
-
Realtime「实时性」
CronJob 对于执行的时机也有要求,如果 CronJob 要求1分钟内执行完毕,如果1分钟后再运行会导致时效性的问题,那么平台也应该考虑相关的设计。
-
Fault Tolerance「容错设计」
CronJob 可能会因为一些外部因素 “执行失败” 或者 “超时”,这时候需要提供一些容错机制,比如:失败重试,超时关闭。
-
Cocurrency「并发控制」
好比于,k8s 中 Deployment 作为一个无状态服务,可以运行多个副本以提高效率;但是相对的,Statefule Set 作为有状态的应用,POD不能随意的扩容,所以需要提供一些并发控制机制,严格的限制 CronJob 的并发数量。
-
Pre-Allocated「预分配」
同样的,某些 CronJob 的优先级比较高,要保证这些任务一直稳定运行。那么需要提供一些预分配机制,可以避免再系统资源处于高位的时候,这些 CronJob 还能继续被调度运行。
总结: 这些要点体现在设计上就是,Schuduler 对 CronJob 的调度控制,来自于 CronJob 的配置和运行状态。CronJob Configuration 包含一些辅助调度控制的配置,如:
{
// ...
"concurrency": 1, // 1 表示这个 CronJob 只能有一个运行中的 Job 实例。
"preAllocated": true, // true 表示这个 CronJob 可以被预分配,这样可以避免系统资源被占满,导致这个 CronJob 无法调度。
"idempotent": "onceMost", // [onceOnly, onceMost, unlimit]
"faultTolerance": {
"maxStartupRetries": 3, // 最大启动失败重试次数
"maxFailureRetries": 3, // 最大执行失败重试次数
"maxFailureRetriesSeconds": "60s", // 最大执行失败重试间隔
"activeDeadlineSeconds": "120s", // 最大执行时间,超过这个时间就会被认为是失败
}, // 容错配置
// ...
"resourceLimit": {
"cpu": "0.1", // CPU 限制
"memory": "128Mi", // 内存限制
}, // 资源限制
}
向分布式演进#
到目前为止,这个定时任务系统的功能已经差不多了,那么是不是意味着这样的设计已经满足需求了?当然没有,比如:
- 单个服务器要承担 交互 、调度 、执行 的压力,那么它能承载的定时任务数量势必会被限制。
- 同样,如果这一台机器出现问题,那么不是就导致所有的定时任务都无法正常运行,影响整个系统的运行。
- 同样,如果我们需求的是一个 PasS 平台,单机不可能 邻近 所有的用户,那么用户请求就很可能经过一些低俗和拥堵的网络链路。
- …
简单的说就是单点问题~,因此我们需要 分布式 设计。
那么怎么把它演进成一个分布式系统呢?
首先应用 CAP 理论,我们可以先确认这个系统应该是 CP 还是 AP 系统呢?对于定时任务系统,高可用不是最重要的,反而是可靠性非常重要。那么可靠性是怎么体现的呢?
- 定时任务不会因为某些节点宕机而不执行
- 强调了最多运行一次,也不会被反复调度执行
- 因为系统异常而未被执行,可以被重新调度执行
- …
因此,我们不需要这个系统有非常高的可用性,偶尔不可用是可以接受的(这是由定时任务的性质决定的)。
对一致性的思考#
思考下,这里是否需要一致性?如果需要,那么是强一致还是最终一致呢? 按照我目前的理解,分布式分为两种(无状态和有状态),针对有状态的服务,可能需要强一致性,也可能最终一致就能满足服务正常运行的需求了。
这里我们分为几个问题来一步步理解:
- 分布式设计之后,对定时任务系统带来的问题是什么?
- 按照我们上面的抽象,怎么确定由哪个节点来承担 scheduler 的职责?– 选主算法
- 如果 scheduler 宕机,应该由谁来接替它的工作?– 选主算法
- 接替者如何“正确的继续”(崩溃时,被调度未结束的和调度中的任务如何处理)?– 集群状态
- 如果集群整体崩溃,那么下次集群重启时,如何弥补宕机期间的任务执行?– 集群状态
- 分布式集群有哪些 状态 ?
- 任务队列(调度器)
- 调度中/执行中的任务(调度器)
- 集群中节点清单和节点状态
- 集群时间/上一次调度时间戳(调度器)
- … 等等跟运行相关的数据
通过上面的QA,再来思考下分布式定时任务平台对于一致性的要求。如果你把整个系统的状态或者日志,放在外部的存储系统中,那么对于定时任务平台也没有特别的一致性要求,因为已经由外部存储系统来维护了。但是如果是保持在系统内部,那么就有要求了,如果说系统中各个节点对于集群的状态存储不一致,那么一旦执行调度任务的节点宕机,其他节点执行调度时上,这样就会导致定时任务的调度出现不一致,这就是一致性的问题。
按照我们的分析,设计的分布式定时任务系统算是一个 CP 系统。因此在设计的时候(暂定为集群内部维护状态),我们通过引入一致性协议来解决一致性问题。如果你学习过分布式理论,亦或者学习过一些分布式软件,如 k8s / etcd / consul 等等,就应该知道 Raft 和 Paxos 这两个一致性协议。
Raft 或者 Paxos 是通过 Leader-Follower 的方式来实现强一致性,那么我们引入 Raft 之后就有如下的架构:

至此,整个分布式定时任务的框架已经成型,我们可以开始设计定时任务的调度器了。
定时任务的调度器#
思考下,调度器的职责是什么?
调度器的职责说简单点就是,在确定在什么时间在哪个节点上运行某个定时任务。时间根据cron规则和cron任务配置的策略来确定,而节点是由调度器根据每个节点的资源负载同时配合cron任务配置的策略来确定。
但是,只是这样而已吗?别忘了现在已经是个分布式集群了,调度器是由leader节点来运行的。如果leadership发生变化,那么接替者还应该检查上一任正在处理的事情,并且把它接着做。举个例子:
A、B、C 三个节点,A作为第一任leader,A正在处理任务1且尚未分配到具体节点执行。这时A宕机了,B作为接替者,那么B成为leader后运行调度器,首先要做的是就是重建调度状态也就是集群状态,并根据集群状态来继续调度。那么怎么重建?
- 加载所有的定时任务,重建时间轮或者定时器。
- 检查 “运行中队列”
- 检查 “待调度队列”
- 检查 “重试队列”
- 其他数据加载(调度时间)
队列为空,当然是最简单的状况,复杂的就是队列不为空情况下怎么处理?运行中不为空,那么恢复结果同步协程;待调度不为空,那么根据调度算法和任务配置的策略来调度;重试队列不为空,那么根据调度算法和任务配置的策略来调度。
任务配置的策略,如不能并发;可以重试;最晚调度时间等等,都会参与调度算法。

用代码来描述的话,就是:
def schedule(self):
if leadership_changed:
# cluster first run or leadership changed
self.start_cron_timer()
self.rebuild_wait_scheduled_queue()
self.rebuild_retry_queue()
self.rebuild_running_queue()
for True:
job = self.get_from_wait_schduled_or_retry_queue()
if job is None:
backoff_delay()
continue
node_id = self.match_node(job)
# build cronjob's RunContext, put it into running queue and
# start a coroutine to synchroize the cronjob's running result.
self.schedule_to_node(node_id, job)定时任务运行时#
任务运行时是为了方便抽象和扩展而来的一个概念,它的职责是接受Leader任务调度请求,运行定时任务并且同步运行结果。但运行时不一定是要集群内的服务器来担任,也可以是外部的系统,如:k8s, containerd, docker, etc,内部只需要把外部系统包装成符合运行时要求的资源即可。
这里,我们假定定时任务的资源类型为容器镜像,运行环境自然就是容器运行时。那么定时任务的运行时,就只需要包装一下k8s的API或者定义CRD即可。
type JobRuntime interface {
// running job
RunJobAsync(ctx context.Context, job *Job, resultCh chan<- *JobResult) (err error)
// cancel job (timeout, etc)
CancelJob(job *Job, reason Reason) (err error)
// query job's status (running, success, failed, etc)
QueryJobResult(job *Job) (result *JobResult, err error)
}因为运行时也算一个无状态节点,所以也没有太多的设计要素。
Kubernetes CronJob#
如果对k8s稍微了解一点,肯定会好奇,为啥不直接使用k8s的cronjob来满足定时任务系统的使用场景呢?当然是可以的,只是这里的主要目的是从头梳理一个(分布式)定时任务系统的功能和设计。在一般场景下 k8s cronjob 已经能够满足使用了,只有个别场景不能直接支持:
- 预分配(优先保证重要的定时任务资源)
- 幂等保证(并发/幂等精细控制)
实时性(超时退出,过时不启动)spec.startingDeadlineSeconds- 异常告警
另外就是在使用上没有那么“方便”(运维可不一定会让开发直接接触k8s~)。
关于 CronJob 的详细控制可以参见 https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/cron-job-v1/#CronJobSpec
个人以为,中小型公司没必要花费大精力去开发分分布式定时任务系统,只需要在k8s的
CronJob/Job的基础上稍微包装一下自己的控制模块就能满足要求。
总结#
定时任务系统是最常用的服务之一,实现方式可大可小,也可以使用linux crontab 服务。本文在不依赖任何服务的前提下,来设计一个分布式定时任务系统,从功能到架构一一梳理。当然,文中提到的功能清单不一定全,只是站在我的角度看到的必要提及的通用功能。架构也不是一成不变的,可以根据自己的场景和目的来设计,只要达到目的即可。
水平有限,如有错误,欢迎勘误指正。